As humans we are fundamentally social creatures. For most people an ordinary day is filled with social interaction. We converse with our family and friends. We talk with our co-workers as we carry out our work. We engage in routine exchanges with familiar strangers at the bus stop and in the grocery store. This social interaction is not just talk: we make eye contact, nod our heads, wave our hands, and adjust our positions. Not only are we busy interacting, we are also remarkably sensitive to the behaviors of those around us. Our world is filled with social cues that provide grist for inferences, planning and action. We grow curious about a crowd that has gathered down the street. We decide not to stop at the store because the parking lot is jammed. We join in a standing ovation even though we didn’t enjoy the performance that much. Social interactions like these contribute to the meaning, interest and richness of our daily life.
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 1 - Introduction to Social Computing
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 2 - Three Best Practices and Three Major Pitfalls
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 3 - Face-to-face Interaction as Inspiration for Designing Social Computing Systems
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 4 - Urban Planning as Inspiration for Designing Social Computing Systems
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 5 - How to do Research in Social Computing
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 6 - Social Computing: Visibility versus Privacy Manipulation versus Persuasion
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 7 - How to integrate Social Computing in the Enterprise
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 8 - The Reason IBM values Social Computing
Author/Copyright holder: Courtesy of Rikke Friis Dam and Mads Soegaard. Copyright terms and licence: CC-Att-ND (Creative Commons Attribution-NoDerivs 3.0 Unported)
Social Computing video 9 - Ethics in Social Computing
4.1 Social Computing: What is it and where did it come from?
Social computing has to do with digital systems that support online social interaction. Some online interactions are obviously social – exchanging email with a family member, sharing photos with friends, instant messaging with coworkers. These interactions are prototypically social because they are about communicating with people we know. But other sorts of online activity also count as social – creating a web page, bidding for something on eBay™, following someone on Twitter™, making an edit to Wikipedia1. These actions may not involve people we know, and may not lead to interactions, but nevertheless they are social because we do them with other people in mind: the belief that we have an audience – even if it is composed of strangers we will never meet – shapes what we do, how we do it, and why we do it.
Thus when we speak of social computing we are concerned with how digital systems go about supporting the social interaction that is fundamental to how we live, work and play. They do this by providing communication mechanisms through which we can interact by talking and sharing information with one another, and by capturing, processing and displaying traces of our online actions and interactions that then serve as grist for further interaction. This article will elaborate on this definition, but first let’s look at where social computing came from.
The roots of social computing date back to the 1960’s, with the recognition that computers could be used for communications and not just computation. As far back as 1961 Simon Ramo spoke of millions of minds connected together and envisioned "a degree of citizen participation ... unthinkable today." (Ramo 1961) Perhaps the best known vision is Licklider and Taylor’s "The Computer as a Communications Device," in which they wrote of the development of “interactive communities of geographically separated people” (Kittur and Kraut 2008) organized around common interests and engaging in rich computer-mediated communication.
The first general purpose computer-mediated communication systems emerged in the 1970’s. Examples include Murray Turoff’s pioneering EMISSARY and EIES systems (Hiltz and Turoff 1993) for “computer conferencing,” PLATO Notes at the University of Illinois (Wooley 1994), and the first mailing lists on the ARPANET. Others followed and the 1980’s saw a flowering of online systems that supported social interaction via online text-based conversation: bulletin board systems, Internet Relay Chat, USENET, and MUDs (see Howard Rheingold’s The Virtual Community for a good history (Rheingold 1993)). The early 1990’s saw continued improvements in basic communications technology – speed, bandwidth and connectivity – and the advent of the Web. Although initially the Web only weakly supported social interaction by allowing people to display content and link to web pages of others (Erickson 1996), it marked the beginning of the widespread authoring and sharing of digital content by the general public.
In my view, social computing came into its own in the late 1990’s and early 2000’s when digital systems became capable of doing more than simply serving as platforms for sharing online content and conversation. The key development was the ability of digital systems to process the content generated by social interaction and feed the results of that processing back into the system. That is, while computer conferencing and its successors served as platforms that supported the production of vast tracts of online conversation, the conversation itself was understood only by humans. Digital systems provided passive media through which people interacted. The advent of modern social computing came when digital systems began to process user-generated content and make use of it for their own purposes – which often involved producing new functionality and value for their users.
A good example of creating value by processing user-generated content is Pagerank™, the algorithm used by the Google1 search engine. The fundamental insight of Pagerank is that the importance of a web page can be estimated by looking at the number of pages that point to it (weighted by the importance of those pages, which can be recursively evaluated in the same way). The underlying assumption is that the act of creating a link to a page is, on the part of a human, an indication that the page is important in one way or another. Thus Pagerank mines and aggregates the results of human judgments as expressed through link creation, and uses it to assess the importance of pages and determine the order in which to display them. This is an early, and very notable, example of the recognition that the digital actions of a large number of people can be tapped to provide a valuable service.
Let us pause, and summarize what we’ve covered so far. Social activity is a fundamental aspect of human life. Not surprisingly, digital systems have accommodated such activity for decades, initially serving as platforms that supported online conversation and other collaborative activity. More recently an important shift has occurred: systems have become able to make use of the products of their users’ social activity to provide further value, and that in turn amplifies the use of the system.
4.2 An example: A Social Computing mechanism
This is abstract, so let us look at a common example, that of the online retailer Amazon.com1. As most readers will be aware, Amazon is an online department store that sells a wide variety of goods, as well as providing an online storefront for other retailers. While there is nothing in Amazon’s core business – selling goods online – that requires social computing, Amazon is notable because it used social computing mechanisms to differentiate itself from other online stores. For illustrative purposes, we will take a close look at Amazon’s product review mechanism.
Amazon enables its users to create online product reviews. Each review consists of a textual essay, a rating of 1 to 5 stars, and the name of its author. Products may garner many reviews – for example, the best-selling book, The Girl with the Dragon Tattoo, has amassed over 2500 reviews.If this were the extent of Amazon’s review mechanism, it would be interesting and useful, but not a social computing mechanism: it would be akin to the early systems that served as platforms for producing user-generated content that was only understood by users. Like those systems, while it is valuable to provide a large number of user-generated reviews, it seems unlikely that viewers will really read through all 2500+ reviews of The Girl with the Dragon Tattoo.
What makes the difference, and moves Amazon’s review mechanism into social computing territory, is that Amazon has been clever about the kind of information it enables its users to enter. Besides the 1-5 star ratings of books from which it can produce averages and other statistics, it allows users to essentially review the reviews: readers can vote on whether a review is “helpful” or not, can flag it as “inappropriate,” and can enter a comment. And readers, in fact, do this. The “most helpful” review of The Girl with the Dragon Tattoo has been voted on by over 2,000 readers, and has received 44 comments.
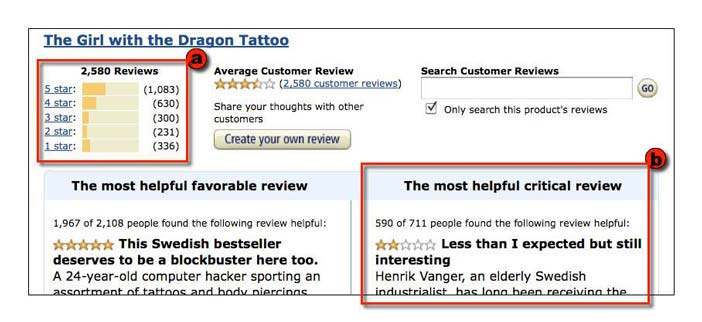
This is significant because users’ votes and ratings can be used (just as Pagerank uses links) to provide valuable information. Using this information, Amazon provides two user interface components that significantly increase the utility of the user-entered information (Figure 1). The first is a graph of the distribution of a book’s ratings that provides viewers with an at-a-glance summary of reviewer sentiment. The second is that it uses the number of “helpful” votes to foreground particular reviews – e.g., the most helpful critical review and the most helpful favorable review.
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.1: The Amazon.com book review summary includes components that show (a) the overall distribution of review ratings, and (b) the "most helpful" (in terms of readers' votes) critical review.
These components – which rely on computations carried out on user input – make it easier for viewers to deal with large amounts of user-generated content. The first integrates the results of all reviews of a book, providing not only the average rating but also the more informative distribution of ratings. The second uses the review’s book ratings in tandem with helpful votes to highlight particular reviews – the most helpful favorable review, and the most helpful critical review. Now, rather than wading through dozens, hundreds or thousands of reviews, the viewer can glance at the overall distribution and read through the “most helpful critical review.” This increases the useful of Amazon’s review information, and most likely increases visits by prospective purchasers. In addition, the possibility of “helpful” votes, and the chance to be recognized as the author of a “most helpful” review, may serve to incent reviewers to write better reviews. All in all, these mechanisms produce virtuous circles: positive feedback loops that promote desirable results.
This aptly illustrates the phase shift that began around the year 2000. Systems emerged that were more than platforms for social interaction: the results of users’ activities began to be usable not just by users, but by the digital systems that supported their activity. Sometimes ordinary content is made digitally tractable by dint of computation, as with Google’s Pagerank algorithm that mines the web to determined linked-to frequency. (Amazon takes this approach as well, when it uses the purchase history of a user to identify those with similar histories, and then provides users-like-you-also-bought recommendations). And sometimes the system requests that users directly enter data in a form that it can make use of – like Amazon’s ratings and “helpful” votes, or the “I like this” and “favorite” votes used in other systems. However it occurs, this ability for the information produced via social interaction to be processed and re-used by the system supporting that interaction is the hallmark of present day social computing.
4.3 The value of Social Computing
Why does social computing matter? Besides the fact that the social interaction supported by social computing systems is intrinsically rewarding, there are a number of ways in which social computing systems can provide value over and above that offered by purely digital systems.
First, social computing systems may be able to produce results more efficiently. Because Amazon can draw on its entire customer base for book reviews, it can provide far more reviews far more quickly than relying on the comparative trickle of reviews produced by Publishers Weekly and other trade outlets. The Girl with the Dragon Tattoo received five reviews within a month of its 2008 publication in English, long before it emerged from obscurity in the English language market. Similarly, Wikipedia, the online encyclopedia, offers over three and a half million articles in the English edition, and can generate articles on current events literally overnight. For example, within an hour of the 2011 Tōhoku earthquake and tsunami in Japan, a three paragraph article had appeared; that, in turn, was edited over 1,500 times in the next 24 hours to produce a well-formed article with maps, photos and 79 references. (As of this writing, nearly ten weeks after the event, the article has been edited over 5,100 times by over 1,200 users, and has 289 references; in the last 30 days it has received nearly 600,000 views.)
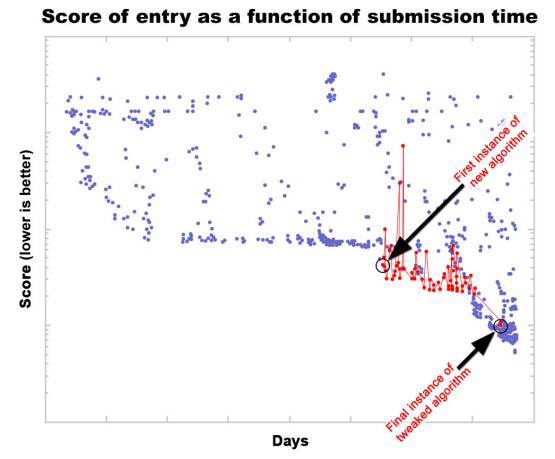
A second way in which social computing can be of value is by increasing the quality of results. A good example is the MatLab1 open source programming contest (MatLab Central 2010, MatLab Central 2011). MatLab is a commercial software package for doing mathematical analysis that uses its own scripting language, and one way its developers promote it is by running a programming contest. Each contest poses a problem, and the challenge is to produce a program that solves it as quickly and completely as possible. Contestants submit the MatLab source code of their programs, and the programs are immediately evaluated, scored, and listed in order of their scores. What makes the contest unusual and interesting is that each entry’s source code is also made publicly available. So when a new top-scoring program is submitted, other contestants will download it and look through the source code for ways to “tweak” it so that it runs slightly faster. The new tweaked program can be submitted, and it and its author will thereby vault ahead of the originator into first place (until another contestant tweaks that entry). As this tweaking process is repeated dozens of times (e.g., Figure 2), the entry is rapidly optimized, drawing on and integrating the specialized knowledge of the community of MatLab programmers (Gulley 2004).
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.2: Collective optimization in the MatLab open source programming contest. Following the introduction of a new algorithm (variants shown in red), contestants refine it, gradually (and noisily) optimizing the algorithm (adapted from MatLab Central 2010)
A third way in which social computing systems can provide value is by producing results that are seen as fairer or more legitimate. Thus, to return to Amazon, one might trust the results of ‘the crowd’ of reviewers more than an ‘official’ reviewer who may have values or biases that are out of sync with the ordinary reader. Another example is the online auction, where multiple people bid for an item – those who lose out may not like the result, but few will argue that it is not legitimate. Stepping out of the digital realm for a moment, note that the rationale for the plebiscites on which democracies are based is not that they produce more rapid decisions, nor that the decisions are necessarily of higher quality, but rather that they are representative and reflect the popular consensus. It is notable that the value of plebiscites and auctions (and even the Amazon review process) can be invalidated by failures in their processes – ballot box stuffing, vote buying and other forms of fraud in elections; shills in auctions; and collusion among bidders and reviewers. In cases like this, it is the legitimacy of the result that has been undermined; demonstrating that the decision was arrived at more quickly or is of higher quality is immaterial. In this case the value of the product is contingent upon the process through which it was derived.
A fourth way in which social computing provides value is by tapping into abilities that are uniquely human. For example, the ESP Game (Ahn and Dabbish 2004), which we will discuss in more detail shortly, is an online game in which a user and an anonymous partner look at an image and try to guess the words that occur to the other person. Both enter words simultaneously, and when they both enter the same word they ‘win’ and receive points; a side effect of this is that the players are producing textual labels for the image – a task that, in general, computer programs cannot perform. Other examples are Galaxy Zoo (Galaxy Zoo 2011, Priedhorsky et al 2007), which asks people to classify galaxies in astronomical photographs by their shapes, and Investigate Your MP (Guardian - guardian.co.uk 2011), which asks participants to read through politicians’ expense reports and flag those that seem suspicious.
To sum up, there are different ways in which social computing systems may produce value: they may produce results more quickly by multiplying effort; they may produce higher quality results by integrating knowledge from multiple participants; they may produce results that are more legitimate by virtue of representing a community; and they may carry out tasks that are beyond the capacity of current digital systems by drawing on uniquely human abilities. But while this value is of great practical import, it should not obscure the most important aspect of social computing: the social interaction itself. Greater efficiency, quality and legitimacy are important benefits, but the reason most people engage with social computing systems lies in the give and take of the interaction itself, the meaning and insight we derive from it, and the connections with others that may be created and strengthened as its result.
4.4 Social Computing as a system: The ESP Game
Thus far we’ve introduced the notion of social computing as an approach that does more than provide a platform for social interaction – it makes use of social interaction to produce various forms of value. The shift to social computing is, at the heart, driven by the ability of digital systems to process the products of the social interaction they support. The products of social interaction have been made digitally tractable, either by dint of digital computation (e.g., Pagerank), or by persuading users to enter information in a form that the digital system can use (e.g., Amazon’s “Helpful” votes and Five-star ratings).
Up to this point our principal example of social computing has been Amazon. However, while Amazon has been enormously successful at making use of social computing mechanisms, if one removed all elements of social computing from Amazon, it would still be able to carry out its basic aim of selling goods online. To expand our understanding of social computing we’ll take a look at some examples of social computing systems – that is, systems that, without social computing mechanisms, simply would not function at all.
The ESP Game (Ahn and Dabbish 2004) is one of a class of systems that have been characterized as performing “human computation.” This type of system is designed so that it enables a large number of people to perform a simple task many times (and often many many times). The art of designing this type of social computing system lies in finding a domain with a difficult problem that can be solved by the massive repetition of a simple (for humans) task, and in figuring out how to motivate the human participants to carry out a simple task many times.
The ESP Game is notable both for its practical success and for the subtleties of design that underlie its apparent simplicity. At a high level the ESP Game sets out accomplish the task of assigning textual labels to images on the web. This is a task that is difficult for computers to perform, but easy for humans. However, while easy for humans, it is not a task that is very interesting to perform, which given that there are billions of images in existence constitutes a problem. What the ESP Game does is to reframe the image labeling process as a game, and by making it fun it succeeds in recruiting large numbers of people to label images. In fact, in its first 5 years of existence, 200,000 people used it to produce more than 50 million image labels (Ahn and Dabbish 2008).
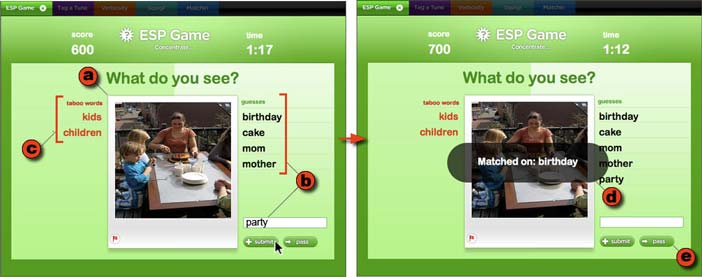
The ESP Game works as follows. A user goes to the web site, where, after a brief wait, he or she is paired with an anonymous partner and the game begins (Figure 3). Both participants are shown (a) an image, and are asked to type (b) words that they believe their partner will type; they may also be shown (c) “taboo words” which cannot be used as guesses. When they achieve (d) a match, they receive points, and move on to a new image; if it proves too difficult to achieve a match, a player can click (e) the “pass” button, which will generate a new image. Each game lasts three minutes, and both participants receive points each time they match on a word.
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.3: The ESP Game in Play mode. The player (a) looks at an image, (b) enters words that describe the image, except that (c) certain words called “taboo words” can’t be chosen. If the other player enters one of the same words, there is (d) a match, and both players get points. If it seems too difficult to come up with good guesses, either player can (e) pass.
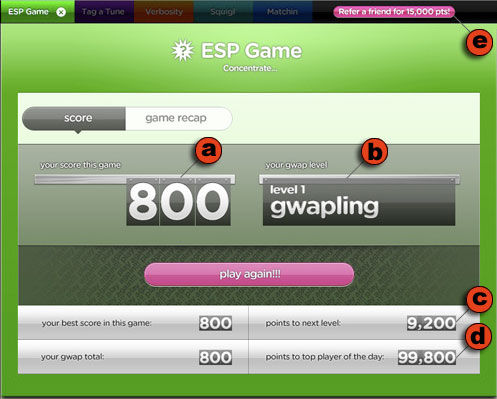
After a game ends the players go their separate ways, each seeing a screen (Figure 4) that recaps how well they did, both in the individual game, and in a cumulative score for all games played. Players are also shown how far they have to go to achieve the next “level,” and how they compare with the highest scoring player for the day.
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.4: The ESP Game Score window. At the end of the game, players are shown (a) their points, (b) their level, (c) points needed to achieve the next level and (d) to beat the best player of the day (d). Players can also earn points by (e) referring friends.
The ESP Game has a number of design features that illustrate issues that social computing systems, in general, must address. As we shall see later, different systems may address these issues differently, but the ESP Game provides a good starting point for grounding this discussion.
4.4.1 Computation
Social computing systems carry out various forms of work to produce value, often by applying algorithms to the results of user-generated content. The ESP Game performs computations by incenting individuals to use their perceptual and cognitive abilities to generate possible labels for an image, and aggregating results across many games to produce a valuable outcome. The result of a single game is a set of images each of which has either a word that both players typed in response to the image, or a “pass.” As multiple pairs play the game on the same images, sets of labels are produced for each image. The best labels will be those that are produced most frequently, and after a while the game will add them to the list of “taboo words” that are not allowed as guesses. This requires players to produce less obvious labels, which are in turn added to the “taboo word” list, until it becomes sufficiently difficult that when presented with an image and its list of taboo words, most players pass. At this point, the image can be ‘retired’ from the game and considered to have a complete set of labels weighted by the frequency with which people produced them. This is a result that cannot be achieved by purely digital systems.
4.4.2 Recruiting and Motivating
The ability of a social computing system to produce value relies on user-generated content, and that means that the system must take measures to ensure that it has a sufficient number of users who are motivated to participate. This was not an issue for Amazon, because the Amazon review mechanism is embedded in the larger Amazon ecosystem, and it happens that some of those attracted to Amazon by its function as an online retailer are interested in reviewing products. This is not the case with the ESP Game – it must do all the work of attracting people. It does this via its use of game-like incentive mechanisms to recruit and motivate its players. People hear about the ESP Game via word of mouth – players can earn points by referring others – and come to play it because it’s fun. Once potential players arrive at the site the problem shifts to engaging them in the game. To that end the ESP Game is nicely designed with bright colors, snappy interaction and appropriate sounds. Many of its features – the limited time, the awarding of points for right answers, a graphical scale showing cumulative points, and the sound of a clock ticking during the final moments of the game – work to motivate the users during game play. When a game ends, other features – cumulative points, user levels, points needed to achieve the next level, and points needed to beat the top player of the day (Figure 4) – encourage the player to “play again!!!” This also provides motivation for players to register, creating online identities that can accumulate points across sessions, and that can vie for positions in the top scores lists for “today,” “this month,” and “all time.” All of these features serve to engage users, motivate them, and encourage them to return – issues that any social computing system will need to address.
4.4.3 Identity and Sociability
Not only must social computing systems attract and motivate their users, but they must make them ‘present’ within the system. Participants in a social computing system generally require identities through which to engage in interaction with others, and identity – especially identity that persists over time – is also bound up with motivation and reputation. The ESP game is actually a relatively low-identity example of a social computing system, in that its participants are not allowed to talk with one another while playing the game, so as to deter cheating. Nevertheless, the ESP Game does take pains to support identity and reinforce the social aspects of the game. As noted, players can register, creating a screen name, an icon, and other elements of a profile. While communication between a pair of players during the game is prohibited, players can join a chat room for the site as a whole (the ESP Game is part of a site called Games with a Purpose). More generally, the design shows the presence of others. Once a user chooses to play, there is a brief wait while the game is “matching you with a partner.” Once a match is made, the player is told the screen name and shown the icon of their partner. Like the incentive mechanism, these social features aim to increase the attraction and interest of the site.
But suppose you show up for a game and there is no one to play with? This is a problem in that not only can the game not take place, but the player who has come to the site may now be less likely to return. The ESP Game deals with this situation by using autonomous software programs called “bots.” If a visitor arrives at the ESP Game site and no one else is there, the visitor will still be paired up with another “player,” but unbeknownst to the visitor the other player will be a bot. The game that ensues will use images that have already been labeled by at least one pair of human players, and the bot will simply replay the responses (and timings) of one of the previous players, giving the human partner the experience of playing against someone else. This use of bots supports the experience of the game, and has another use that we will look at shortly.
4.4.4 Directing and Focusing Activity
Another issue that social computing systems need to deal with is how to focus or otherwise shape the activities of their users. In the ESP Game, this is done via taboo words. As already described, taboo words serve to increase the breadth of the set of labels generated for an image by ruling out those that many previous pairs of players have produced. Taboo words also shape the set of labels produced in a more subtle way: they can prime players to pay attention to certain aspects of the image (Ahn and Dabbish 2008) (e.g., an image with “green” as a taboo word might incline players to name other colors in the image). The ESP Game could use other approaches to focusing work such as selecting images from particular known sets (e.g., images of paintings), or recruiting players from particular populations (e.g., art school students). Many social computing systems have mechanisms, of one sort or another, that try to focus or otherwise control the nature of the computation the system performs.
4.4.5 Monitoring and Controlling Quality
While humans can perform computations that are difficult or impossible for digital systems, it is also the case that human-generated results may be inaccurate – thus many social computing systems need to address the issues of monitoring and controlling the quality of results produced. Quality problems may result from ignorance, unnoticed bias, or intentional choice. In the case of the ESP Game, the primary threat to quality is cheating. That is, the game-like incentive mechanisms work so well that players may play with the goal of getting points, rather than accurately labeling images.
As the ESP Game has developed, various cheating strategies have been identified and circumvented. Solo cheating occurs when a person logs on twice and tries to play themselves – this can be detected and prevented by IP matching. Dyadic cheating occurs when two players devise a word entry strategy (e.g., “one”, “two”, “three”) and try to log on at the same moment in the hopes of being paired up – this can be prevented by having a long enough waiting period (“matching you with a partner”) and a sufficient number of waiting players that it is unlikely that conspirators will be matched. If there are not enough players waiting to ensure a good likelihood of a random match, the ESP Game can use bots as surrogate players, as previously described. Finally, cheating can occur en mass when someone posts a word entry strategy and starting times on a public web site. This approach can be detected by a sudden spike in activity (or a sudden increase in performance), and countered by, once again, pairing players with bots.
These examples of cheating raise several points. First, with respect to designing social computing systems, cheating can be dealt with. It is simply necessary to identify cheating strategies and block them – or at least lower their probability of success to a point where it is easier to win by using the system as the designers intended. Second, note that cheating is an issue only in certain types of social computing systems. Cheating occurs primarily in systems where the incentive mechanism is unrelated to the system’s purpose. Third, note that since cheating removes the fun from the game, its existence is apt testimony to the power of the ESP Game’s game-like incentive mechanisms.
4.4.6 Summary
In this section we’ve looked at social computing systems as systems, using the ESP Game as an illustrative example. Unlike the Amazon review mechanism, which was embedded in the larger Amazon ecology, the ESP Game needs to function as a complete system, solving the problems of recruiting participants, giving them an identity within the system, focusing their attention on tasks that need doing, incenting them to do the task, and monitoring and controlling the quality of the results. The ESP Game does this by drawing on game design thinking. It is successful because the tasks on which it is focused are simple, well-formed and thus amenable to very rapid, very iterative interaction – and this, in turn, is well suited to game play.
On the other hand, while von Ahn and his colleagues have proven to be quite ingenious in their ability to find domains amenable to this approach (see Ahn and Dabbish 2008), many problems do not break down so neatly into such simple well-formed tasks. Yet, as we shall see, social computing systems – albeit with different approaches to the above issues – can still make headway.
4.5 Social Computing as a system: Wikipedia
In this section we examine what is, in the view of many, the most successful example of a social computing system: Wikipedia. Besides its success Wikipedia is of interest because it offers a stark contrast with the ESP Game. Whereas the ESP Game attracts a steady stream of anonymous users who perform a simple task embedded in a game, Wikipedia is more of a community, with a core of committed participants who interact with one another while performing a variety of complex tasks. Wikipedia has also proved to be popular with researchers, making it a superbly studied example of a social computing system. Thus, our examination of Wikipedia will add breadth to our understanding of social computing.
As most readers will know, Wikipedia is, in the words of its slogan, “the free encyclopedia that anyone can edit.” With a few exceptions, every article in Wikipedia has an “edit” tab that allows anyone to edit the article (Figure 5, b). On the face of it, this is a bit of a paradox: how can one have an authoritative source of knowledge that anyone can change at any moment? And yet it works well enough. While generalizing about millions of articles in all stages of development is difficult, it is fair to say that Wikipedia’s accuracy is surprising. Studies have shown that some classes of articles are comparable in accuracy to their counterparts in the Encyclopedia Britannica (Giles 2005), and, more generally, that an article’s quality tends to increase with the number of edits it has received (Wilkinson and Huberman 2007, Kittur and Kraut 2008).
Regardless of how it compares to the quality of traditional encyclopedias, Wikipedia has been remarkably successful. With over three and a half million articles in the English edition alone, it is among the most visited sites on the web. And, as we saw earlier, it can generate lengthy, well-researched articles very quickly – literally over night at times. As encyclopedias go, this puts Wikipedia in a class by itself.
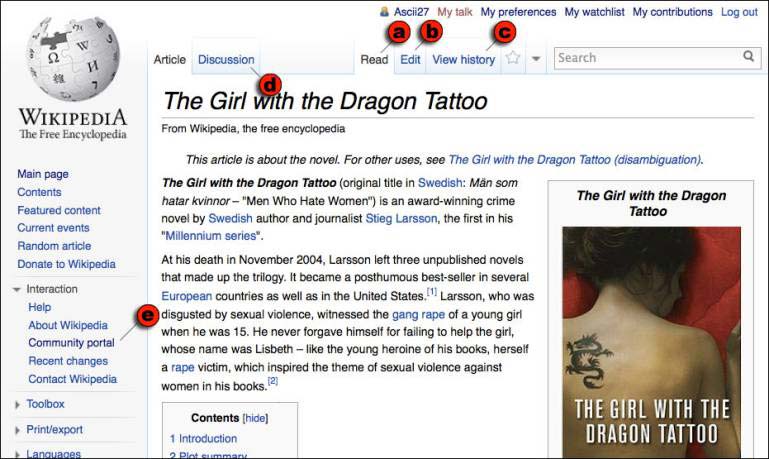
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.5: The Wikipedia article page for The Girl with the Dragon Tattoo. Most visitors come (a) to read, but they can also (b) edit the article, (c) view its history, or (d) read its discussion page. Those wishing more involvement in Wikipedia can visit (e) the Community portal.
4.5.1 Contributing to Wikipedia
Let’s begin our examination by considering what contributors do in Wikipedia. While the aim is to create an encyclopedia article, clearly this is too large a task. Contributors do not author fully formed articles all at once. Instead, articles coalesce out of the accretion of smaller efforts. One contributor writes an article “stub,” others add paragraphs, and still others expand, modify and condense existing text. Some may add links to references, others may correct typos and grammatical errors, and still others may contribute images. This is how the article on The Girl with the Dragon Tattoo developed. Starting from an article stub that appeared at about the time of the book’s English language publication, the article grew gradually – with bursts of activity when movies were released – until today it is a well-formed article that has been edited over 600 times by 395 contributors. As of this writing, it has been viewed 234,000 times in the last 30 days.
The key question to be asked about Wikipedia is this: How it is that Wikipedia articles improve in quality over time? How is it that Wikipedia determines that a particular change – whether it’s replacing one word, adding a paragraph, or reorganizing an article – is a change for the better? Sometimes it’s obvious – for example, correcting a typo – but more often than not it isn’t obvious. The answer is that Wikipedia relies on users to judge the quality of changes to an article. But this is not much of answer. What is important is – and what constitutes the art of how Wikipedia is designed – is the way in which it supports its users in making such judgments. As we shall see, Wikipedia musters a complex array of social computing mechanisms in support of the activities of its contributors.
4.5.2 Judging Quality and Making Changes
Two things have to happen for users to be able to judge the quality of a change: individual changes must be made visible; and users must be able to express their opinions on the desirability of a change. Wikipedia accomplishes this through its revision history mechanism (Figure 6) that is accessed by the “View History” tab on each article. The revision history lists all the changes made to an article and provides a link that enables the viewer to undo the change. Thus, if the entire text of the article has been replaced with a string of obscenities – an action more frequent than one might expect, and referred to as “vandalism” – the viewer can click on an “undo” link and revert the article to its prior state. And indeed, one of the early and surprising research findings about Wikipedia was that such acts of vandalism were typically discovered and reverted within two to three minutes (Viégas et al 2004) this result has continued to hold up over time (Priedhorsky et al). This becomes less surprising in view of the fact that Wikipedia provides a mechanism called a “watchlist” that allows users to monitor changes to articles they care about. For instance, the article for The Girl with the Dragon Tattoo currently has 59 people watching it.
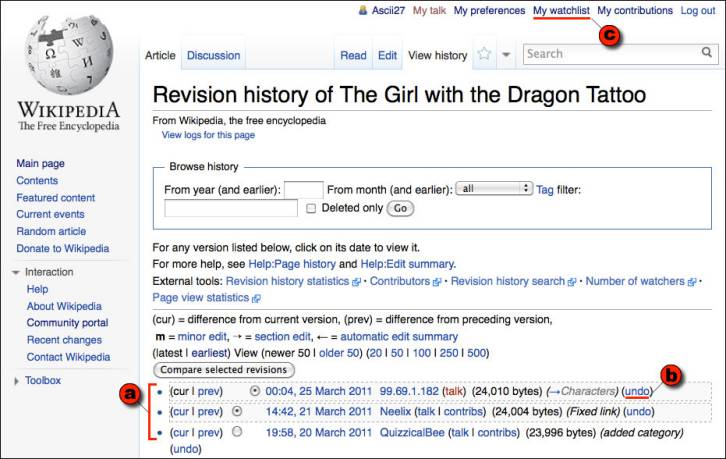
Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.6: A Wikipedia revision history page. The revision history shows (a) a list of all changes made to an article, (b) provides a way to undo each change, and (c) enables those who care about an article to add it to a “watchlist” so changes to it can be watched.
However, there is more to supporting quality than detecting and undoing vandalism. After all, vandalism is obviously a change for the worse. Much vandalism is trivial to detect. The more difficult issue is how to resolve subtler questions such as whether an explanation is clear or obscure. Or whether the reorganization of a paragraph improves it. Or whether a particular picture is helpful. Or whether a way of describing something departs from the neutrality desirable in an encyclopedia. To make decisions about these types of quality issues people need to communicate – and the revision history page lays the foundation for such communication. To see this, take a look at the section of the revision history shown in Figure 7.

Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.7: A segment of a Wikipedia revision history showing four revisions. For each revision there is (a) a way of comparing to other revisions, (b) a time and date stamp, (c) links to the user who made the change, (d) information about the change, and (e) a way to undo the change.
The revision page contains a list of every change made to its article. Each entry in the list contains (a) a way to compare that change to other versions of the article, (b) the time and date of the change, (d) other information about the change), and (e) a way of undoing the change. Of particular interest for our purposes is that the entry also contains (c) information about who made the change. Specifically, the entry contains
the name or IP address of the person who made the revision
a link to that person’s talk page (which provides a way to communicate with them), and
a link to a list of contributions that person has made to Wikipedia (which provides a way to judge how experienced they are)
This expands the revision history into a social mechanism by introducing identity and communication channels. That is, rather than just seeing a change and deciding whether to revert it, the viewer can see who made the change, find out something about the user (via the link to their user page), their experience with Wikipedia (via the link to their contributions page), and even discuss their change with them (via the link to their talk page). Indeed, researchers have shown that the quality of Wikipedia articles is not simply related to the number of people who edit them, but that for this relationship to hold these contributors must also be engaging in communication and collaboration (Kittur and Kraut 2008, Wilkinson and Huberman 2007). For example, investigating the first entry in Figure 7, one can quickly discover that Varlaam is a highly experienced Wikipedia editor who has been awarded a “Master Editor” barnstar and has contributed to dozens (at least) of articles on books and films. Even if one disagreed with Varlaam’s change, one might hesitate to simply undo it, given the level of experience in evidence. The second entry is a different story – it has only an IP address associated with it, which means that this person has not registered with Wikipedia. Nevertheless, by clicking on the IP Address link, one can quickly see that the person at this IP address has been making regular contributions to Wikipedia over the last six months on a variety of articles related to films, and one can even take a look at individual contributions and see that this person has been a positive contributor.
4.5.3 Identity and Communication
The links in the revision history page illustrate another aspect of Wikipedia: it has a variety of mechanisms that support identity and communication. Every person who contributes to Wikipedia has a “user page,” a “contributions page,” and a “talk page.” The user page is like a home page, where a contributor can post whatever they like about themselves. Often this will include information that tells others about their experience and knowledge vis a vis topics they like to edit. This page is also where Wikipedia contributors display awards they’ve received from the Wikipedia community (Wikipedia has a custom of encouraging contributors to give symbolic awards – the best known example being a “barnstar” – to others who have helped on an article or project). In addition to the user page, there are two other automatically generated pages. The contribution page lists every change that that person has made to Wikipedia, and includes a “diff” link that shows precisely what changes the user has made. And the talk page supports conversation with that user. Both the talk and contribution pages have direct links from the entries in the revision history. In addition to user “talk pages,” there are also article “discussion pages” for discussions about the content of an article. For example, the discussion page for The Girl with the Dragon Tattoo has seven discussions, one on whether it is legitimate to characterize the protagonist as “incorruptible,” another about why the English title is so different from the original Swedish title, and yet another about whether to include a claim about an authorship dispute.
While all of these ways of finding out what people have done and talking with them might seem like a recipe for chaos, overall it appears to work. People do talk with one another, and their discussions tend to be about whether and how to change the content of the articles. For instance, more than half of the comments on talk pages are requests for coordination (Viégas et al 2007). And although argument is common, contributors often reach a rough consensus. What is interesting about this is not that people reach consensus, but rather how they reach agreement. Wikipedia has an extensive set of policies and guidelines that govern it (Figure 8a). For instance, one of Wikipedia’s fundamental principles is that articles should strive for a neutral point of view, and try to fairly represent all significant views that have been published by reliable sources. Another policy is verifiability – that is, that readers should be able to check that material in Wikipedia that is likely to be challenged must be attributed to a reliable source through an in-line citation.
What is important here, for the purposes of understanding social computing, is not the policies and guidelines themselves, but rather that policies and guidelines function to provide an infrastructure for discussion. Ideally, contributors who differ argue about whether something is in accord with the policies or not, rather than attacking one another. Or contributors discuss and evolve the policy itself. Just like Wikipedia articles, Wikipedia policies have their own pages with “Edit,” “Discussion,” and “View History” tabs, and, just like articles, policies and guidelines are extensively discussed and developed. Thus the article on the Neutral Point of View policy (Figure 8b) has seven sections that cover about 7 pages (4,300 words), and has been edited by over 1700 users over the decade it has been in existence; it has been viewed over 37,000 times in the last 30 days which, while not nearly as much as The Girl with the Dragon Tattoo, nevertheless indicates that it is an actively used resource. Both the use of policies to guide editing, and the collective evolution of policies by the community of users are discussed at length in the aptly named article, Don’t Look Now, But We’ve Created a Bureaucracy (Butler et al 2008).

Author/Copyright holder: Unknown (pending investigation). Copyright terms and licence: Unknown (pending investigation). See section "Exceptions" in the copyright terms below.
Figure 4.8: Wikipedia has a well-articulated set of guidelines and (a) policies, each of which is embodied as a Wikipedia article with (b) a detailed outline and (c) a thorough discussion, and which can be revised in the same way as ordinary articles.
So what we’ve seen here is that although random people can and do click the edit tab and make changes on the spot, much of the work that happens in Wikipedia does not play out so simply. Mechanisms that support identity, communication, and the application of policies come together to enable a complex social process the guides the creation and development of high quality articles.
Given this, it is perhaps not surprising that there is a core of contributors, often referred to as Wikipedians, who are responsible for the majority of contributions. While there are various ways of defining what counts as a contribution, researchers agree that a small percentage of editors contribute the majority of content – for instance, the top 10% of contributors by number of edits provide between 80 and 90% of the viewed content (Priedhorsky et al 2007). More generally, Wikipedians do more work, make contributions that last longer (before someone else changes them), and invoke community norms to justify their edits more frequently (Panciera et al 2009). In sum, although Wikipedia “is the free encyclopedia that anyone can edit,” not just anyone tends to edit it, and there is much more to “editing” than meets the eye.
4.5.4 Summary
Wikipedia is a remarkable achievement. It is a self-governing system that produces well-structured articles – sometimes literally over night – that are sufficiently useful that it is among the most visited sites on the web. In our examination of Wikipedia we asked how it is that Wikipedia articles improve over time, noting that, for example, obvious problems like vandalism are repaired within two to three minutes. In what should by now be a recognizable motif, we saw that Wikipedia, as a system, ‘knows’ something about its content. Specifically, Wikipedia keeps track of every change ever made to every article, and it makes those individual changes visible and actionable on the revision history page of each article. Wikipedia (or, strictly speaking, the design of Wikipedia) recognizes that some changes are worth keeping, and others are not, and that by making it easy for users to view and pass judgment on those changes it can support the creation of increasingly higher quality articles. And because quality can be a subtle and contentious issue, Wikipedia provides ways for users to talk with one another about changes, and provides policies that guide users in making consistent decisions about those changes. In this we see the modus operandi of social computing: users add content, and the system processes that content in ways that make it more usable (in this case, by increasing the ability of people to discuss, evaluate and keep or undo changes in keeping with Wikipedia policy).
4.6 Social Computing: The big picture
Throughout this article we’ve looked at social computing in terms of how social computing systems work as systems: they create platforms for social interaction whose results can be drawn upon by the system to add value. This is natural because we have proceeded by looking closely at examples. However, I’d like to wrap this up by looking at social computing in a subtly different way – as a type of approach to computation.
In my view, social computing is not so much about computer systems that accommodate social activity, but rather it is about systems that perform computations on information that is embedded in a social context. That is:
Social computing refers to systems that support the gathering, processing and dissemination of information that is distributed across social collectives. Furthermore, the information in question is not independent of people, but rather is significant precisely because it linked to people, who are in turn associated with other people.
At the core of this definition is the linking of information to identity. That is, information is associated with people, and, for the purposes of social computing, the association of information with identity matters. “Identity” does not necessarily mean that information is associated with a particular, identifiable individual. For the purposes of social computing, identity can run the gamut from guaranteeing distinctiveness (i.e., that different pieces of information come from distinct individuals, as one would want in a plebiscite), to knowing some of the characteristics of each individual with whom information is associated (a set of book purchases by a distinct but anonymous individual), to knowing a person’s real world identity.
A second element of this definition is the idea that individuals are associated with one another in social collectives. Social collectives can be teams, communities, organizations, markets, cohorts, and so forth. That is, just as information is linked to a person, so are individuals associated with one another: it matters who is associated with whom, and how and why they are related. That is notto say that individuals are necessarily linked to one another in person to person relationships. Individuals may be mutual strangers, and “associated” only because they happen to share some characteristic like an interest in a particular book, or in MatLab programming.
In fact, in some cases, social computing systems are predicated on the assumption that individuals will be mutually anonymous. For example, markets and auctions attract participants with shared interests, but the underlying social computing mechanisms are designed to prevent individuals from identifying one another. A market functions most effectively when the actions of individuals are independent; otherwise, individuals can collude to affect the functioning of the market to benefit themselves, as when auctions are manipulated via shilling (false bids intended to raise the final price). In short, it is precisely because the linkage between information and individuals matters that, for the purposes of some social computations, it must be suppressed.
A third element of the definition is that social computing systems have mechanisms for managing information, identity, and their interrelationships. This follows from the mention of the gathering, use and dissemination of information distributed across social collectives. Whereas an ordinary computational system need only manage information and its processing, social computing systems must also manage the social collective, which is to say that it must provide a way for individuals to have in-system identities, relate information to those identities, and manage relationships among the identities (which, as noted, can include maintaining mutual anonymity, as in the case of markets). Social computing systems can take a number of approaches to this, and the sort of social architecture it employs fundamentally shapes the nature of the system.
4.7 What's next?
Social computing is a large area, and it is one that is growing rapidly. The examples we’ve looked at – Pagerank, the Amazon review mechanism, the MatLab Programming Contest, the ESP Game, and Wikipedia – just scratch the surface. New examples of social computing mechanisms and systems spring up seemingly over night.
This article has focused on ‘conventional’ examples of social computing. That is, they are web-based and largely draw on and appeal to educated audiences spread across the industrialized world. We are beginning to see, and will see many more, social computing systems that are designed expressly for mobile devices, that are targeted locally rather than globally, and that will include or be expressly targeted at populations in developing regions. These new domains, and the challenges they pose, will shape the further development of social computing.
Social computing is evolving with great rapidity. Designers and scholars from a wide range of disciplines – behavioral economics, computer science, game design, human-computer interaction, psychology, and sociology, to name a few – are actively studying social computing systems and applying insights gleaned from their disciplines. It is difficult to predict the future, but it seems safe to say that social computing mechanisms and systems will continue to transform the way we live, learn, work and play.
4.8 Where to learn more
The roots of social computing stretch back decades. A good starting point for those interested in the forerunners of social computing is Howard Rhinegold’s The Virtual Community (Rheingold 1993). For those interested in a deeper taste of history, Starr Roxanne Hiltz and Murray Turoff’s The Network Nation (Hiltz and Turoff 1993) – originally published in the late 70’s and revised in the early 90’s – offer an early yet comprehensive vision (portions of which still seem remarkably prescient) of forms of social intelligence and action mediated by computer networks.
For those interested the new wave of social computing systems that have been the focus of this article, the best place to begin are books that lay out the underlying rationale for social computing by showing what can be achieved by large scale collective action. The Wisdom of Crowds, by James Suroweicki (Suroweicki 2004), is an excellent introduction to a wide range of examples of social computation. Arriving in the same territory from a different direction is Eric von Hippel’s Democratizing Innovation (Hippel 2005), which examines how innovation arises from groups and communities and argues for redesigning business practices and government policies to take advantage of large scale innovation.
Those who wish a more detailed understanding of social computing systems as systems – how to design them, how to launch them, how to maintain them – are at the frontiers of knowledge. A variety of workshops and symposia focus on various ‘slices’ through social computing. Wikisym is a central place for research involving the use of wiki’s for collaboration, and the best place to plumb the growing pool of research on Wikipedia. The Human Computation workshop (Human Computation Workshop 2011), now in its third year, examines systems like the ESP game that engage large numbers of people in performing computations and other tasks. There is currently no annual conference that covers the full range of social computing systems, although perhaps that role will be filled by the Collective Intelligence conference to be inaugurated in 2012.
4.8.0.1 WikiSym - International Symposium on Wikis
4.9 Acknowledgements
Thanks to Robert Farrell for helpful comments on the penultimate draft of this article.
4.10 Notes
1. Amazon.com is a trademark of Amazon.com, Inc.; Google and Pagerank are trademarks of Google, Inc.; eBay is a trademark of eBay, Inc.; MatLab is a trademark of The Mathworks; Twitter is a trademark of Twitter, Inc.; Wikipedia is a registered trademark of the Wikimedia Foundation.
4.11 References
Ahn, Luis von and Dabbish, Laura (2004): Labeling images with a computer game. In: Dykstra-Erickson, Elizabeth and Tscheligi, Manfred (eds.) Proceedings of ACM CHI 2004 Conference on Human Factors in Computing Systems April 24-29, 2004, Vienna, Austria. pp. 319-326
Ahn, Luis von and Dabbish, Laura (2008): Designing games with a purpose. In Communications of the ACM, 51 (8) pp. 58-67
Butler, Brian, Joyce, Elisabeth and Pike, Jacqueline (2008): Don't look now, but we've created a bureaucracy: the nature and roles of policies and rules in wikipedia. In: Proceedings of ACM CHI 2008 Conference on Human Factors in Computing Systems April 5-10, 2008. pp. 1101-1110
Erickson, Thomas (1996): The world wide web as social hypertext. In Communications of the ACM, 31 (1) pp. 15-17
Giles, Jim (2005): Internet encyclopaedias go head to head. In Nature, 438 pp. 900-901
Guardian, The (2011). Investigate Your MP's Expenses. Retrieved 19 June 2011 from The Guardian - guardian.co.uk:
Gulley, Ned (2004): In praise of tweaking: a wiki-like programming contest. In Interactions, 11 (3) pp. 18-23
Hiltz, Starr Roxanne and Turoff, Murray (1993): The Network Nation: Human Communication via Computer. MIT Press
Hippel, Eric von (2005): Democratizing Innovation. The MIT Press
Human Computation Workshop (2011). The Human Computation Workshop. Retrieved 22 July 2011 from Human Computation Workshop: http://www.humancomputation.com/
Kittur, Aniket and Kraut, Robert E. (2008): Harnessing the wisdom of crowds in wikipedia: quality through coordination. In: Proceedings of ACM CSCW08 Conference on Computer-Supported Cooperative Work 2008. pp. 37-46
Kittur, Aniket, Suh, Bongwon, Pendleton, Bryan A. and Chi, Ed H. (2007): He says, she says: conflict and coordination in Wikipedia. In: Proceedings of ACM CHI 2007 Conference on Human Factors in Computing Systems 2007. pp. 453-462
Licklider, J. C. R. and Taylor, Robert W. (1968): The Computer as a Communication Device. In Science and Technology, pp. 21-31
MatLab Central (2010). MatLab Central: MatLab Programming Contest. Retrieved 19 June 2010 from MatLab Central: http://www.mathworks.com/matlabcentral/contest/
MatLab Central (2011). MatLab Central: Molecule Contest Analysis. Retrieved 19 June 2011 from MatLab Central:
Panciera, Katherine, Halfaker, Aaron and Terveen, Loren (2009): Wikipedians are born, not made: a study of power editors on Wikipedia. In: GROUP09 - International Conference on Supporting Group Work 2009. pp. 51-60
Priedhorsky, Reid, Chen, Jilin, Lam, Shyong (Tony) K., Panciera, Katherine, Terveen, Loren and Riedl, John (2007): Creating, destroying, and restoring value in wikipedia. In: GROUP07: International Conference on Supporting Group Work 2007. pp. 259-268
Raddick, M. Jordan, Bracey, Georgia, Gay, Pamela L., Lintott, Chris J., Murray, Phil, Schawinski, Kevin, Szalay, Alexander S. and vandenBerg, Jan (2010): Galaxy Zoo: Exploring the Motivations of Citizen Science Volunteers. In Astronomy Education Review, 9 (1)
Ramo, Simon (1961): The Scientific Extension of the Human Intellect. In Computers and Automation, 10 (2) pp. 9-12
Rheingold, Howard (1993): The Virtual Community: Homesteading on the Electronic Frontier. Reading, MA, The MIT Press
Surowiecki, James (2004): The Wisdom of Crowds. Anchor
Viégas, Fernanda B., Wattenberg, Martin and Dave, Kushal (2004): Studying cooperation and conflict between authors with history flow visualizations. In: Dykstra-Erickson, Elizabeth and Tscheligi, Manfred (eds.)Proceedings of ACM CHI 2004 Conference on Human Factors in Computing Systems April 24-29, 2004, Vienna, Austria. pp. 575-582
Wilkinson, Dennis M. and Huberman, Bernardo A. (2007): Cooperation and quality in wikipedia. In: Proceedings of the 2007 International Symposium on Wikis 2007. pp. 157-164
Woolley, David R. (1994). PLATO: The emergence of online community. Retrieved 19 June 2011 from http://thinkofit.com/plato/dwplato.htm
Zoo, Galaxy (2011). Galaxyzoo.org. Retrieved 19 June 2011 from Galaxy Zoo
